Quorum Components¶
In addition to single node failures, the cluster may split into several components due to network failure. A component is a set of nodes that are connected to each other, but not to the nodes that form other components. In these situations, only one component can continue to modify the database state to avoid history divergence. This component is called the Primary Component.
Under normal operations, your Primary Component is the cluster. When cluster partitioning occurs, Galera Cluster invokes a special Quorum algorithm to select one component as the Primary Component. This guarantees that there is never more than one Primary Component in the cluster.
Note
In addition to the individual node, quorum calculations also take into account a separate process called garbd. For more information on its configuration and use, see Galera Arbitrator.
Weighted Quorum
The current number of nodes in the cluster defines the current cluster size. There is no configuration setting that allows you to define the list of all possible cluster nodes. Every time a node joins the cluster, the total cluster size increases. When a node leaves the cluster, gracefully, the cluster size decreases. Cluster size determines the number of votes required to achieve quorum.
Galera Cluster takes a quorum vote whenever a node does not respond and is suspected of no longer being a part of the cluster. You can fine tune this no response timeout using the evs.suspect_timeout parameter. The default setting is 5 seconds.
When the cluster takes a quorum vote, if the majority of the total nodes connected from before the disconnect remain, that partition stays up. When network partitions occur, there are nodes active on both sides of the disconnect. The component that has quorum alone continues to operate as the Primary Component, while those without quorum enter the non-primary state and begin attempt to connect with the Primary Component.
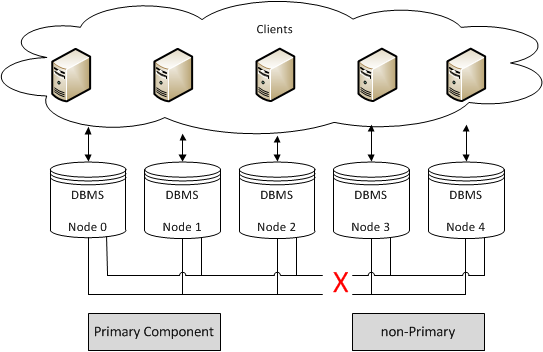
Quorum requires a majority, meaning that you cannot have automatic failover in a two node cluster. This is because the failure of one causes the remaining node automatically go into a non-primary state.
Clusters that have an even number of nodes risk split-brain conditions. If should you lose network connectivity somewhere between the partitions in a way that causes the number of nodes to split exactly in half, neither partition can retain quorum and both enter a non-primary state.
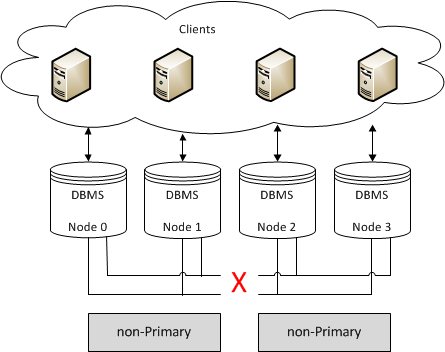
In order to enable automatic failovers, you need to use at least three nodes. Bear in mind that this scales out to other levels of infrastructure, for the same reasons.
- Single switch clusters should use a minimum of 3 nodes.
- Clusters spanning switches should use a minimum of 3 switches.
- Clusters spanning networks should use a minimum of 3 networks.
- Clusters spanning data centers should use a minimum of 3 data centers.
Split-Brain Condition
Cluster failures that result in database nodes operating autonomous of each other are called split-brain conditions. When this occurs, data can become irreparably corrupted, such as would occur when two database nodes independently update the same row on the same table. As is the case with any quorum-based system, Galera Cluster is subject to split-brain conditions when the quorum algorithm fails to select a Primary Component.
For example, this can occur if you have a cluster without a backup switch in the event that the main switch fails. Or, when a single node fails in a two node cluster.
By design, Galera Cluster avoids split-brain condition. In the event that a failure results in splitting the cluster into two partitions of equal size, (unless you explicitly configure it otherwise), neither partition becomes a Primary Component.
To minimize the risk of this happening in clusters that do have an even number of nodes, partition the cluster in a way that one component always forms the Primary Cluster section.
4 node cluster -> 3 (Primary) + 1 (Non-primary)
6 node cluster -> 4 (Primary) + 2 (Non-primary)
6 node cluster -> 5 (Primary) + 1 (Non-primary)
In these partitioning examples, it is very difficult for any outage or failure to cause the nodes to split exactly in half.
For more information on configuring and managing the quorum, see Resetting the Quorum.
Quorum Calculation
Galera Cluster supports a weighted quorum, where each node can be assigned a weight in the 0 to 255 range, with which it will participate in quorum calculations.
The quorum calculation formula is
Where:
- \(p_i\) Members of the last seen primary component;
- \(l_i\) Members that are known to have left gracefully;
- \(m_i\) Current component members; and,
- \(w_i\) Member weights.
What this means is that the quorum is preserved if (and only if) the sum weight of the nodes in a new component strictly exceeds half that of the preceding Primary Component, minus the nodes which left gracefully.
You can customize node weight using the pc.weight parameter. By default, node weight is 1, which translates to the traditional node count behavior.
You can change the node weight during runtime by setting the pc.weight parameter.
SET GLOBAL wsrep_provider_options="pc.weight=3";
Galera Cluster applies the new weight on the delivery of a message that carries a weight. At the moment, there is no mechanism to notify the application of a new weight, but will eventually happen when the message is delivered.
Warning
If a group partitions at the moment when the weight-change message is delivered, all partitioned components that deliver weight-change messages in the transitional view will become non-primary components. Partitions that deliver messages in the regular view, will go through quorum computation with the applied weight when the subsequential transitional view is delivered.
In other words, there is a corner case where the entire cluster can become non-primary component, if the weight changing message is sent at the moment when partitioning takes place. Recovering from such a situation should be done either by waiting for a re-merge or by inspecting which partition is most advanced and by bootstrapping it as a new Primary Component.
Weighted Quorum Examples
Now that you understand how quorum weights work, here are some examples of deployment patterns and how to use them.
Weighted Quorum for Three Nodes
When configuring quorum weights for three nodes, use the following pattern:
node1: pc.weight = 2
node2: pc.weight = 1
node3: pc.weight = 0
Under this pattern, killing node2 and node3 simultaneously preserves the Primary Component on node1. Killing node1 causes node2 and node3 to become non-primary components.
Weighted Quorum for a Simple Master-Slave Scenario
When configuring quorum weights for a simple master-slave scenario, use the following pattern:
node1: pc.weight = 1
node2: pc.weight = 0
Under this pattern, if the master node dies, node2 becomes a non-primary component. However, in the event that node2 dies, node1 continues as the Primary Component. If the network connection between the nodes fails, node1 continues as the Primary Component while node2 becomes a non-primary component.
Weighted Quorum for a Master and Multiple Slaves Scenario
When configuring quorum weights for a master-slave scenario that features multiple slave nodes, use the following pattern:
node1: pc.weight = 1
node2: pc.weight = 0
node3: pc.weight = 0
...
noden: pc.weight = 0
Under this pattern, if node1 dies, all remaining nodes end up as non-primary components. If any other node dies, the Primary Component is preserved. In the case of network partitioning, node1 always remains as the Primary Component.
Weighted Quorum for a Primary and Secondary Site Scenario
When configuring quorum weights for primary and secondary sites, use the following pattern:
Primary Site:
node1: pc.weight = 2
node2: pc.weight = 2
Secondary Site:
node3: pc.weight = 1
node4: pc.weight = 1
Under this pattern, some nodes are located at the primary site while others are at the secondary site. In the event that the secondary site goes down or if network connectivity is lost between the sites, the nodes at the primary site remain the Primary Component. Additionally, either node1 or node2 can crash without the rest of the nodes becoming non-primary components.
Related Documents