Cluster Deployment Variants¶
A Galera Cluster will consist of multiple nodes, preferably three or more. Each node is an instance of MySQL, MariaDB or Percona XtraDB that you convert to Galera Cluster, allowing you to use that node as a cluster base.
Galera Cluster provides synchronous multi-primary replication. You can treat the cluster as a single database server that listens through many interfaces. To appreciate this, consider a typical n-tier application and the various benefits that would come from deploying it with Galera Cluster.
No Clustering
In the typical n-tier application cluster without database clustering, there’s no concern for database replication or synchronization.
Internet traffic will be filtered down to your application servers, all of which read and write from the same DBMS server. Given that the upper tiers usually remain stateless, you can start as many instances as you need to meet the demand from the internet. Each instance stores its data in the data tier.
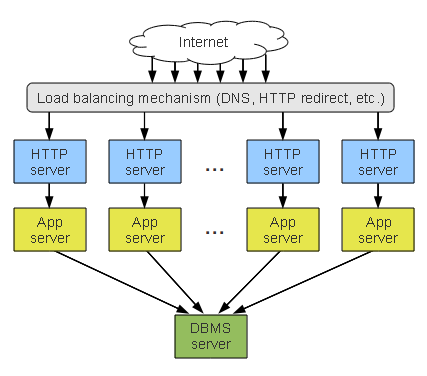
No Clustering
This solution is simple and easy to manage, but has a particular weakness in the data tier’s lack of redundancy.
For example, if for any reason the DBMS server become unavailable, your application also becomes unavailable. This is the same whether the server crashes or it has been shut down for maintenance.
Similarly, this deployment also introduces performance concerns. While you can start as many instances as you need to meet the demands on your web and application servers, they can only so much load on the DBMS server can be handled before the load begins to slow end-user activities.
Whole Stack Clustering
In the typical n-tier application cluster you can avoid the performance bottleneck by building a whole stack cluster.
Internet traffic filters down to the application server, which stores data on its own dedicated DBMS server. Galera Cluster then replicates the data through to the cluster, ensuring it remains synchronous.
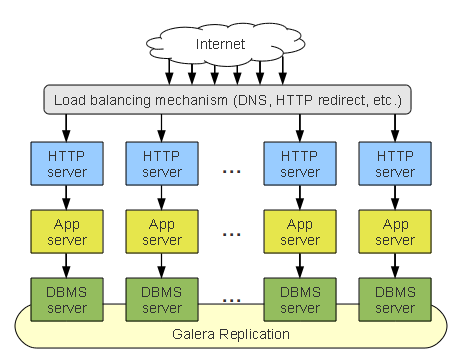
Whole Stack Cluster
This solution is simple and easy to manage, especially if you can install the whole stack of each node on one physical machine. The direct connection from the application tier to the data tier ensures low latency.
There are, however, certain disadvantages to whole stack clustering that you should consider:
- Lack of Redundancy: When the database server fails, the whole stack fails. This is because the application server uses a dedicated database server. If the database server fails there’s no alternative for the application server, so the whole stack goes down.
- Inefficient Resource Usage: A dedicated DBMS server for each application server will be overused. This is poor resource consolidation. For instance, one server with a 7 GB buffer pool is much faster than two servers with 4 GB buffer pools.
- Increased Unproductive Overhead: Each server reproduces the work of the other servers in the cluster. This redundancy is a drain on the server’s resources.
- Increased Rollback Rate: Given that each application server writes to a dedicated database server, cluster-wide conflicts are more likely. This can increase the likelihood of corrective rollbacks.
- Inflexibility: There is no way for you to limit the number of primary nodes or to perform intelligent load balancing.
Despite the disadvantages, however, this setup can prove very usable for several applications, depending on your needs.
Data Tier Clustering
To compensate for the shortcomings in whole stack clusters, you can cluster the data tier separately from your web and application servers.
With data tier clustering, the DBMS servers form a cluster distinct from your n-tier application cluster. The application servers treat the database cluster as a single virtual server, making calls through load balancers to the data tier.
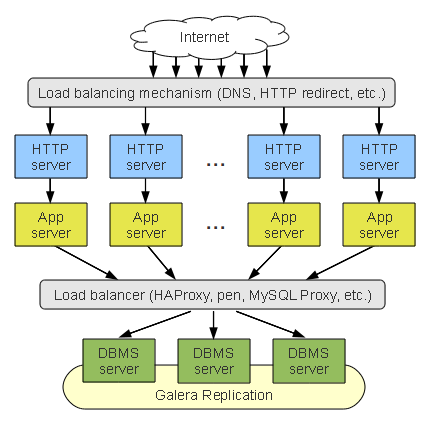
Data Tier Clustering
In a data tier cluster, the failure of one node doesn’t effect the rest of the cluster. Furthermore, resources are consolidated better and the setup is flexible. That is to say, you can assign nodes different roles using intelligent load balancing.
There are, however, certain disadvantages to consider in data tier clustering:
- Complex Structure: Since load balancers are involved, you must back them up in case of failure. This typically means that you have two more servers than you would otherwise, as well as a failover solution between them.
- Complex Management: You need to configure and reconfigure the load balancers whenever a DBMS server is added to the cluster or removed.
- Indirect Connections: The load balancers between the application cluster and the data tier cluster increase the latency for each query. As a result, this can easily become a performance bottleneck. You will need powerful load balancing servers to avoid this.
- Scalability: This setup doesn’t scale well over several datacenters. Attempts to do so may reduce any benefits you gain from resource consolidation, given that each datacenter must include at least two DBMS servers.
Data Tier Clustering with Distributed Load Balancing
One solution to the limitations of data tier clustering is to deploy them with distributed load balancing. This method roughly follows the standard data tier cluster method, but includes a dedicated load balancer installed on each application server.
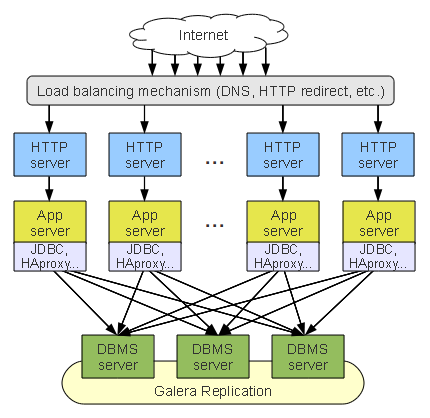
Data Tier Cluster with Distributed Load Balancing
In this deployment, the load balancer is no longer a single point of failure. Furthermore, the load balancer scales with the application cluster and thus is unlikely to become a bottleneck. Additionally, it minimizes the client-server communications latency.
Data tier clustering with distributed load balancing has the following disadvantage:
- Complex Management: Each application server deployed for an n-tier application cluster will require another load balancer that you need to set up, manage and reconfigure whenever you change or otherwise update the database cluster configuring.
Aggregated Stack Clustering
Besides the deployment methods already mentioned, you could set up a hybrid method that integrates whole stack and data tier clustering by aggregating several application stacks around single DBMS servers.
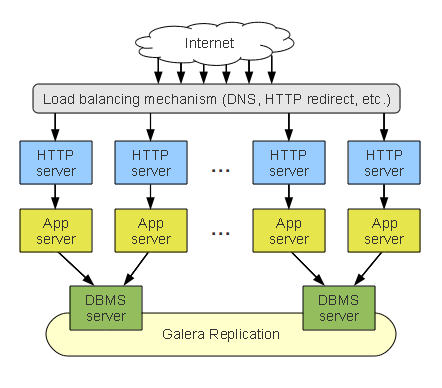
Aggregated Stack Clustering
This layout improves on the resource utilization of the whole stack cluster, while maintaining its relative simplicity and direct DBMS connection benefits. It’s also how a data tier cluster with distributed load balancing will look if you were to use only one DBMS server per datacenter.
The aggregated stack cluster is a good setup for sites that are not very large, but are hosted at more than one datacenter.