Database Replication¶
Database replication refers to the frequent copying of data from one node—a database on a server—into another. Think of a database replication system as a distributed database, where all nodes share the same level of information. This system is also known as a database cluster.
The database clients, such as web browsers or computer applications, do not see the database replication system, but they benefit from close to native DBMS behavior.

Primaries and Replicas
Many Database Management Systems replicate the database.
The most common replication setup uses a primary/replica relationship between the original data set and the copies.
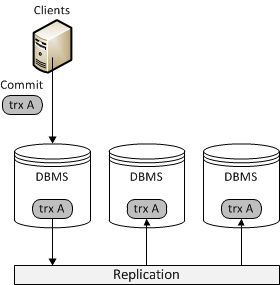
Primary/Primary Replication
In this system, the primary database server logs the updates to the data and propagates those logs through the network to the replicas. The replica database servers receive a stream of updates from the primary and apply those changes.
Another common replication setup uses multi-primary replication, where all nodes function as primaries.
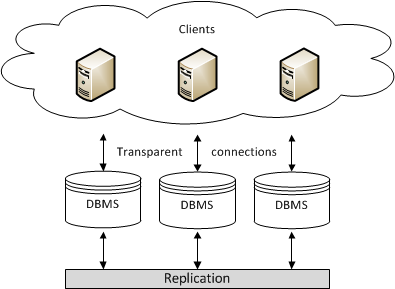
Multi-primary Replication
In a multi-primary replication system, you can submit updates to any database node. These updates then propagate through the network to other database nodes. All database nodes function as primaries. There are no logs available and the system provides no indicators sent to tell you if the updates were successful.
Asynchronous and Synchronous Replication
In addition to the setup of how different nodes relate to one another, there is also the protocol for how they propagate database transactions through the cluster.
- Synchronous Replication Uses the approach of eager replication. Nodes keep all replicas synchronized by updating all replicas in a single transaction. In other words, when a transaction commits, all nodes have the same value.
- Asynchronous Replication Uses the approach of lazy replication. The primary database asynchronously propagates replica updates to other nodes. After the primary node propagates the replica, the transaction commits. In other words, when a transaction commits, for at least a short time, some nodes hold different values.
Advantages of Synchronous Replication
In theory, there are several advantages that synchronous replication has over asynchronous replication. For instance:
- High Availability Synchronous replication provides highly available clusters and guarantees 24/7 service availability, given that:
- No data loss when nodes crash.
- Data replicas remain consistent.
- No complex, time-consuming failovers.
- Improved Performance Synchronous replications allows you to execute transactions on all nodes in the cluster in parallel to each other, increasing performance.
- Causality across the Cluster Synchronous replication guarantees causality across the whole cluster. For example, a
SELECTquery issued after a transaction always sees the effects of the transaction, even if it were executed on another node.
Disadvantages of Synchronous Replication
Traditionally, eager replication protocols coordinate nodes one operation at a time. They use a two phase commit, or distributed locking. A system with \(n\) number of nodes due to process \(o\) operations with a throughput of \(t\) transactions per second gives you \(m\) messages per second with:
What this means that any increase in the number of nodes leads to an exponential growth in the transaction response times and in the probability of conflicts and deadlock rates.
For this reason, asynchronous replication remains the dominant replication protocol for database performance, scalability and availability. Widely adopted open source databases, such as MySQL and PostgreSQL only provide asynchronous replication solutions.
Solving the Issues in Synchronous Replication
There are several issues with the traditional approach to synchronous replication systems. Over the past few years, researchers from around the world have begun to suggest alternative approaches to synchronous database replication.
In addition to theory, several prototype implementations have shown much promise. These are some of the most important improvements that these studies have brought about:
- Group Communication This is a high-level abstraction that defines patterns for the communication of database nodes. The implementation guarantees the consistency of replication data.
- Write-sets This bundles database writes in a single write-set message. The implementation avoids the coordination of nodes one operation at a time.
- Database State Machine This processes read-only transactions locally on a database site. The implementation updates transactions are first executed locally on a database site, on shallow copies, and then broadcast as a read-set to the other database sites for certification and possibly commits.
- Transaction Reordering This reorders transactions before the database site commits and broadcasts them to the other database sites. The implementation increases the number of transactions that successfully pass the certification test.
The certification-based replication system that Galera Cluster uses is built on these approaches.